Project Goal:
Create a chatbot to assist perspective students in navigating the MS Applied Data Science admissions process at UChicago that incorporates information from the student website.
Approach:
I used Playwright to scrape the program and admissions websites, then chunked and embedded the data using OpenAI embeddings. I stored the embeddings in ChromaDB and implemented the retrieval-augmented generation pipeline using LangChain with GPT-4.0 as the language model. The chatbot provides detailed, context-aware answers to user questions based on official admissions content.
Evaluation:
I evaluated the system using RAGAS for quantitative performance metrics and conducted extensive human testing to ensure high-quality, reliable responses.
Deployment:
I containerized my solution, and it is currently undergoing further deployment to be implemented on the program website. For testing purposes, I created a simple UI with Streamlit (pictured below).
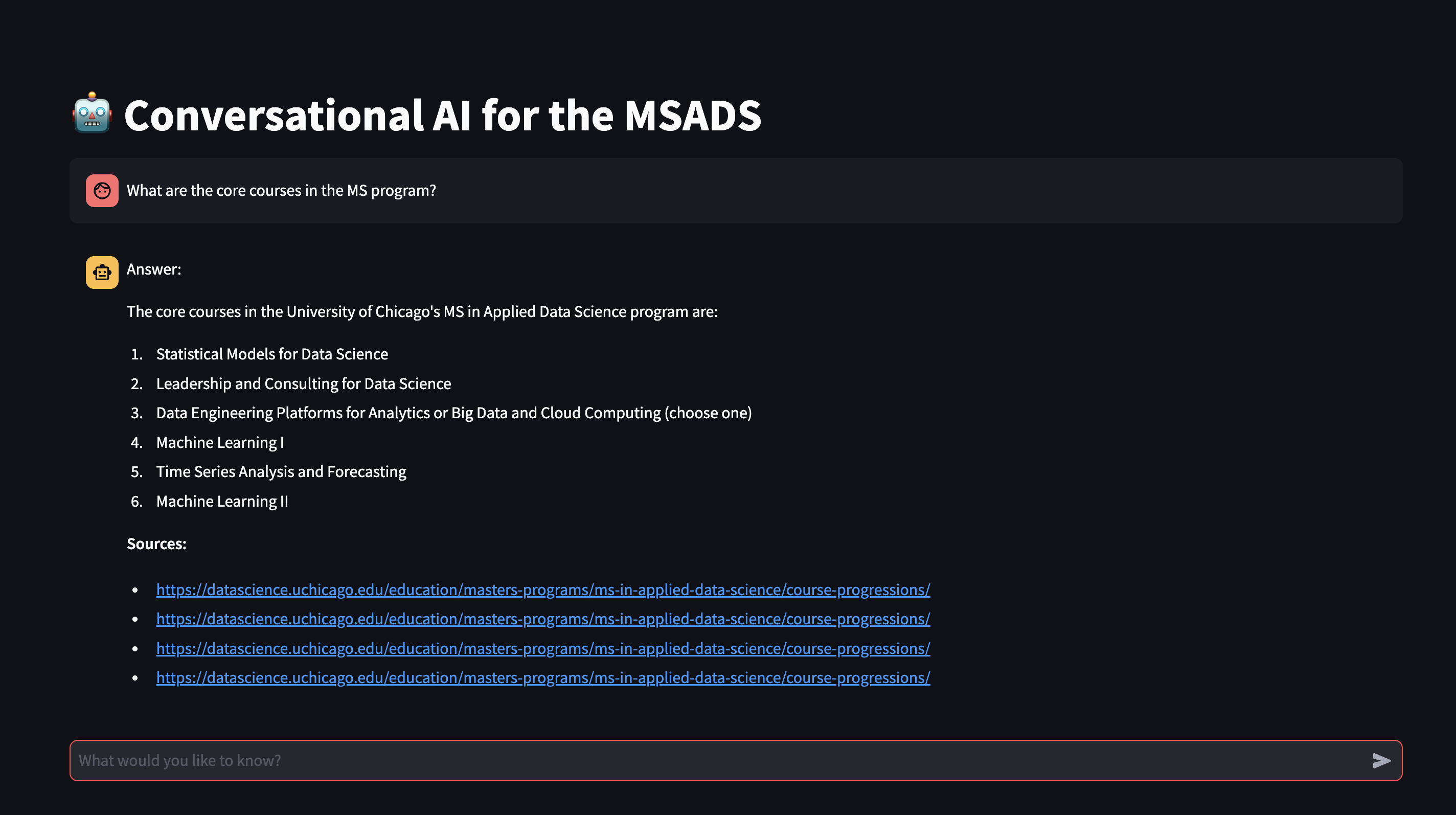
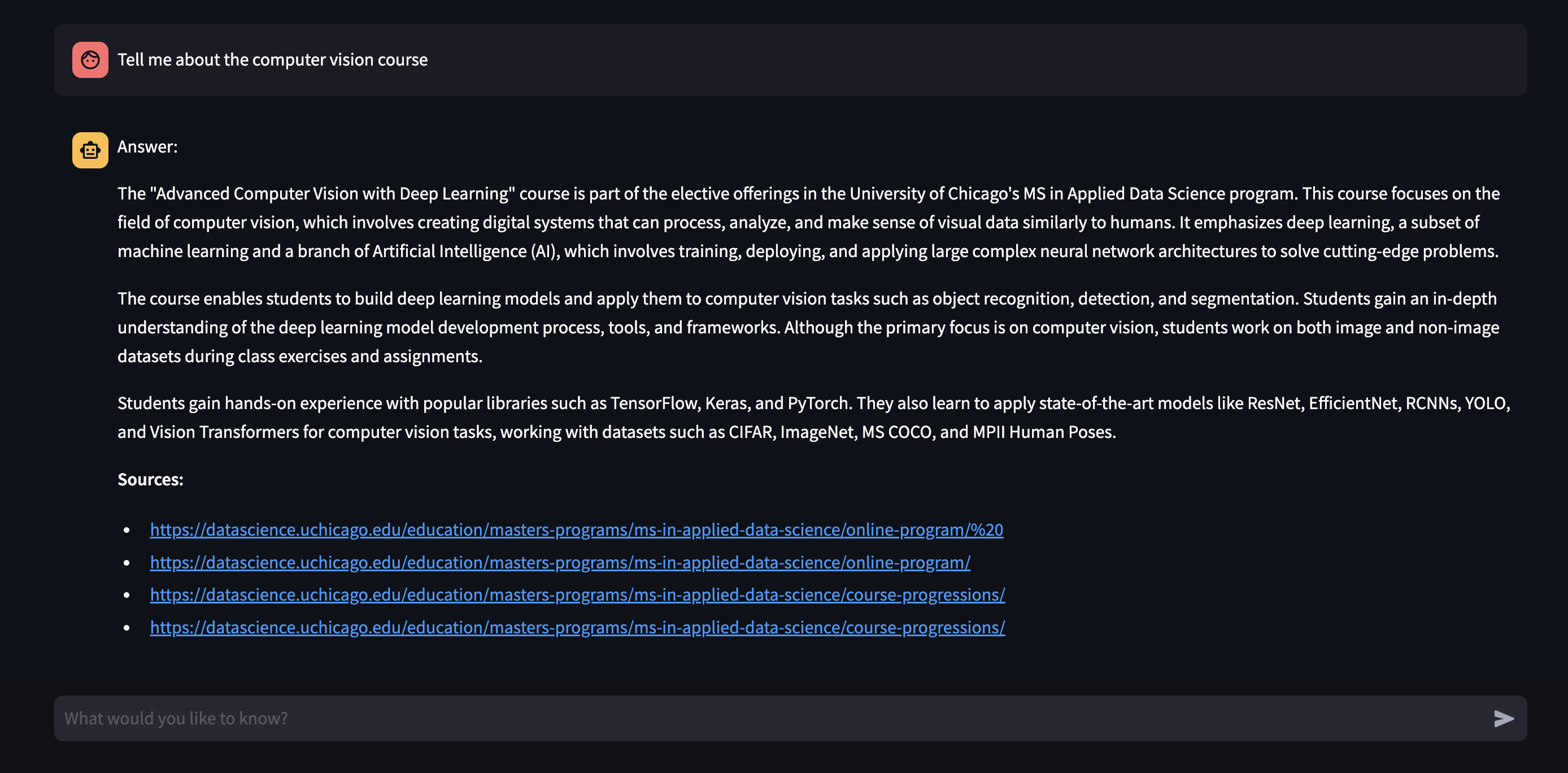
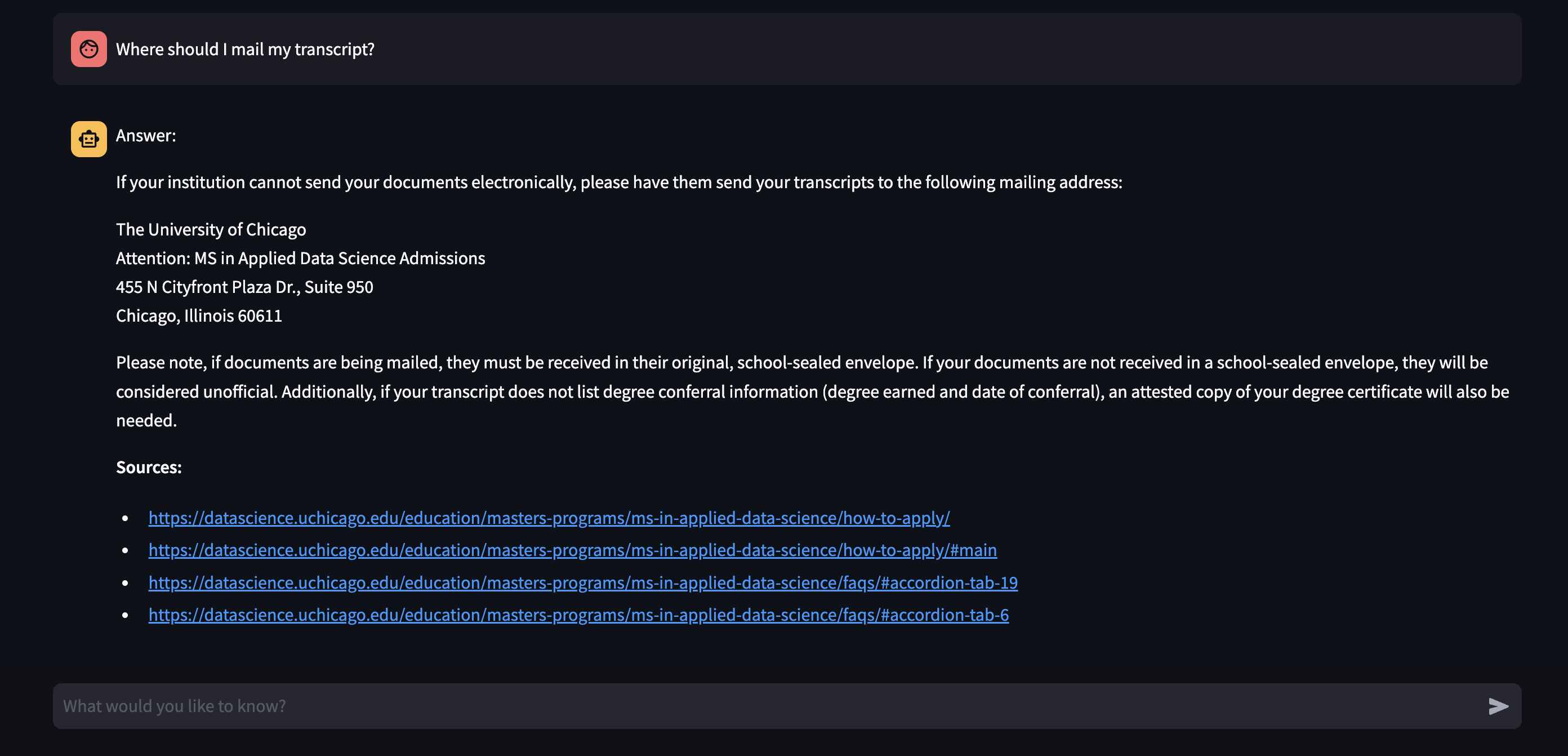
Highlighted Code Sections:
import os
from playwright.async_api import async_playwright
from langchain.schema import Document
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from urllib.parse import urljoin, urlparse
# Extract page text and list items from fully rendered browser context
async def extract_full_page_text_with_playwright(url, wait_time=5):
docs = []
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True, args=["--no-sandbox"])
page = await browser.new_page()
await page.goto(url, timeout=60000)
await asyncio.sleep(wait_time)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Extract visible text and list items safely
raw_text = await page.evaluate('(() => { const listItems = Array.from(document.querySelectorAll("li")).map(li => "- " + li.innerText.trim()); const pageText = document.body.innerText; return pageText + "[Bullet Points]" + listItems.join(""); })()')
docs.append(Document(page_content=raw_text, metadata={"source": url}))
await browser.close()
return docs
# Crawl site recursively
async def crawl_website_with_rendering_async(base_url, max_pages=20, delay=1):
visited = set()
to_visit = [base_url]
all_docs = []
while to_visit and len(visited) < max_pages:
url = to_visit.pop(0)
if url in visited:
continue
try:
page_docs = await extract_full_page_text_with_playwright(url)
all_docs.extend(page_docs)
visited.add(url)
print(f"Crawled: {url}")
# Discover additional sub-links
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True, args=["--no-sandbox"])
page = await browser.new_page()
await page.goto(url, timeout=60000)
anchors = await page.eval_on_selector_all("a", "nodes => nodes.map(n => n.href)")
for link in anchors:
if urlparse(link).netloc == urlparse(base_url).netloc and link.startswith(base_url):
if link not in visited and link not in to_visit:
to_visit.append(link)
await browser.close()
await asyncio.sleep(delay)
except Exception as e:
print(f" Failed to crawl {url}: {e}")
return all_docs
# Build RAG pipeline
async def build_rag_pipeline(base_url):
all_docs = await crawl_website_with_rendering_async(
base_url, max_pages=20
)
if not all_docs:
raise ValueError(" No content extracted")
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(all_docs, embedding=embeddings, persist_directory="/content/drive/MyDrive/chroma_store")
vectordb.persist()
retriever = vectordb.as_retriever()
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever, return_source_documents=True)
return rag_chain
# Run
base_url = "https://datascience.uchicago.edu/education/masters-programs/ms-in-applied-data-science/"
rag = await build_rag_pipeline(base_url)